meta 在上周终于发布了 llama3,目前先发布的是 8b 以及 70b 两个模型,还有多模态以及一个 400b 规模的模型正在训练,预计在夏天发布,即使是 70b 的模型也已经足够强大,在 llm 竞技场的英文评价下已经仅次于 gpt-4 超过现在的所有模型。
模型详细介绍:
- 性能测试:
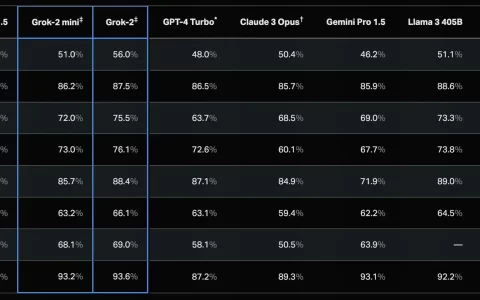
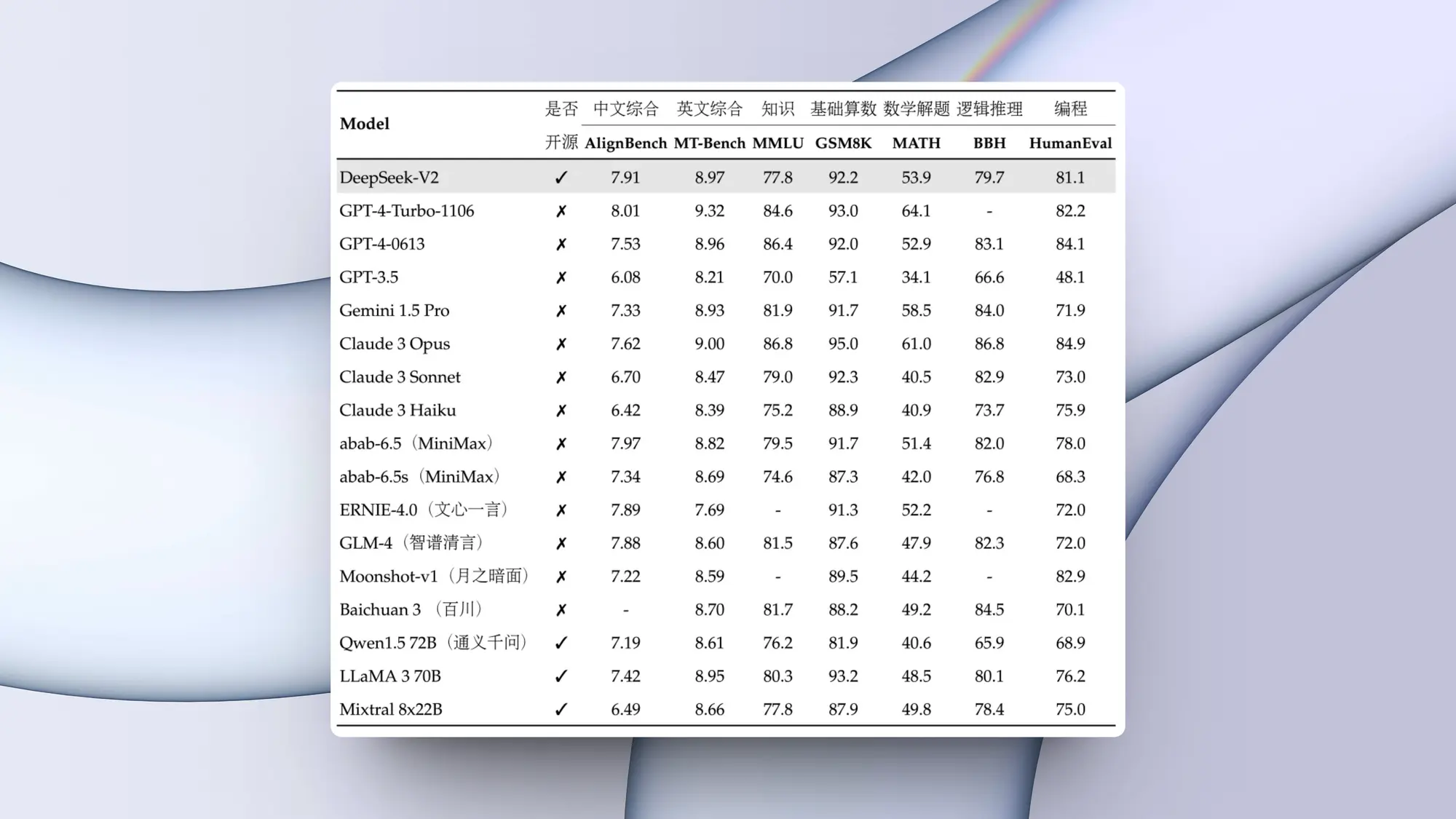
预训练和指导微调模型是目前 8b 和 70b 参数尺度上最好的模型。
后期训练程序的改进大大降低了错误拒绝率,提高了对齐度,并增加了模型响应的多样性。
还发现,推理、代码生成和指令跟踪等能力也有了很大提高,这使得 llama 3 的可操控性更强。
- 模型架构:
llama 3 使用了一个 128k 的标记化器,它能更有效地编码语言,从而大幅提高模型性能。
为了提高 llama 3 模型的推理效率,在 8b 和 70b 大小的模型中都采用了分组查询关注 (gqa)。
在 8,192 个词组的序列上对模型进行了训练,并使用掩码来确保自我关注不会跨越文档边界。
- 训练:
llama 3 在超过 15t 的词库上进行了预训练,这些词库都是从公开来源收集的。
训练数据集是 llama 2 的七倍,包含的代码数量也是 llama 2 的四倍。
为了应对即将到来的多语言使用情况,llama 3 的预训练数据集中有超过 5% 的高质量非英语数据,涵盖 30 多种语言。
开发了一系列数据过滤管道。这些管道包括使用启发式过滤器、nsfw 过滤器、语义重复数据删除方法和文本分类器来预测数据质量。
- 如何使用:
llama 3 模型将很快在 aws、databricks、google cloud、hugging face、kaggle、ibm watsonx、microsoft azure、nvidia nim 和 snowflake 上提供,并得到 amd、aws、戴尔、英特尔、nvidia 和高通提供的硬件平台的支持。
可以在meta官方助手meta ai上体验。
- 未来支持:
在接下来的几个月里,将推出新的功能、更长的上下文窗口、更多的型号尺寸和更强的性能,并将与大家分享 llama 3 研究论文。
原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/yun295812.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重