mixtral8x22b在只公布了一个磁力链接之后,又正式发布了模型的技术报告:
- mixtral 是一个稀疏混合专家(smoe)模型,它在141b个参数中仅激活了39b个,为其大小提供了无与伦比的成本效率。
- mixtral 8x22b具有多种优势,包括对英语、法语、意大利语、德语和西班牙语的流利支持,强大的数学和编程能力,以及64k令牌的上下文窗口,允许从大型文档中精确回忆信息。
- 该模型以apache 2.0许可证发布,是完全开放的,旨在促进ai领域的创新和合作。
- mixtral 8x22b在性能和成本效率方面均优于其他模型,其稀疏激活模式使其比任何密集的70b模型都要快,同时比任何其他开放权重模型都更有能力。
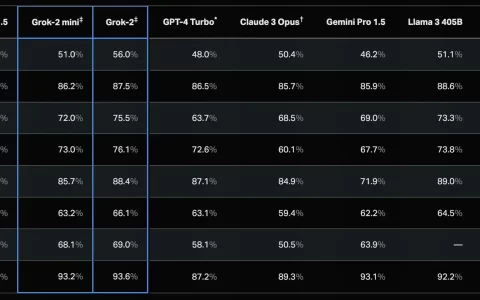
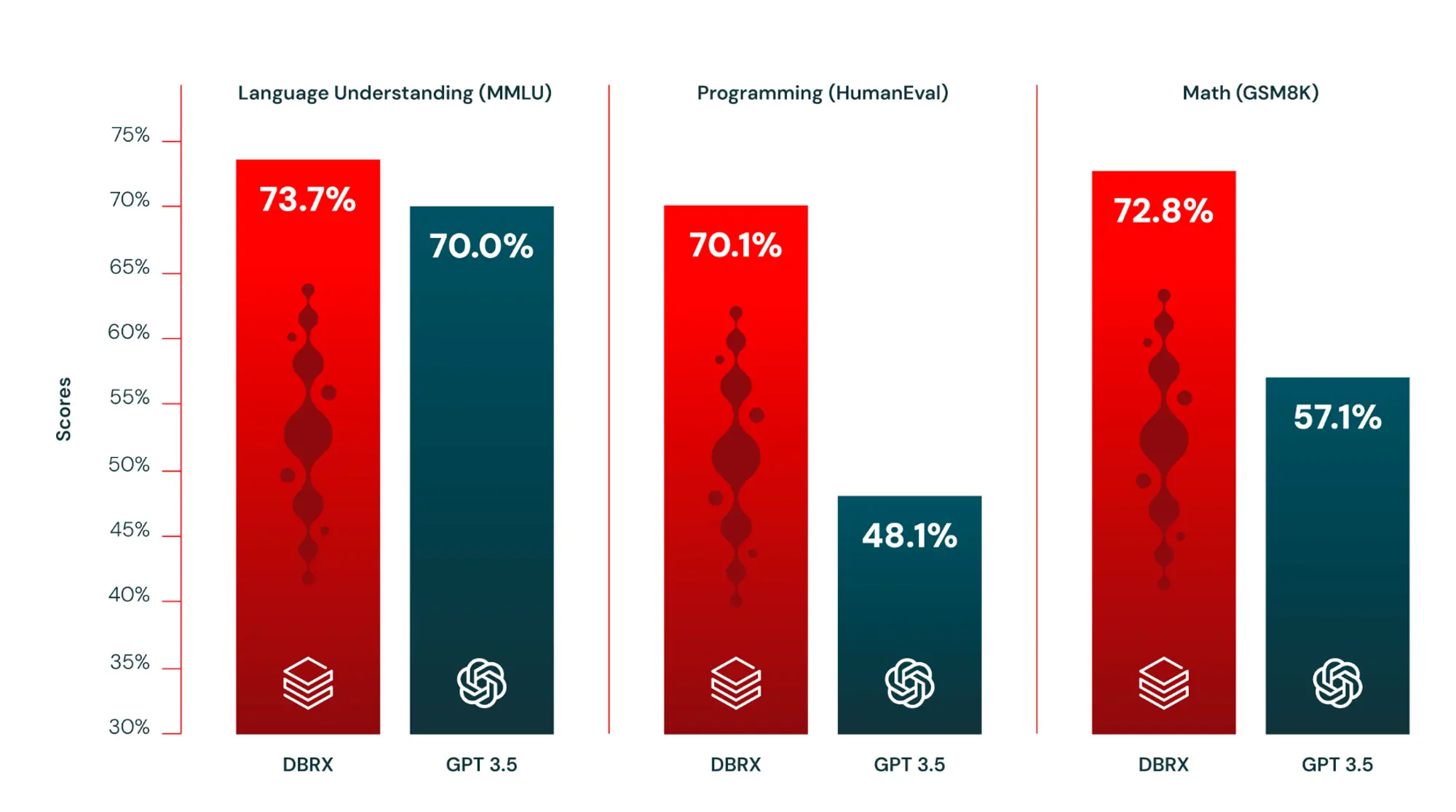
- 在标准行业基准测试中,mixtral 8x22b在推理、知识、多语言能力、数学和编程任务方面的表现均优于其他开放模型。
- 特别是,在数学和编程任务中,mixtral 8x22b的表现最佳,其在gsm8k maj@8的得分为90.8%,在math maj@4的得分为44.6%。
- mistral ai鼓励开发者社区探索mixtral 8x22b,并加入他们以共同定义ai前沿。
mixtral 还发布了他们新版本的。
这些分词器不仅支持文本与 tokens 之间的互转,还增添了对工具的解析和结构化对话处理的能力。
还发布了应用程序接口中使用的验证和规范化代码。
项目地址:https://github.com/mistralai/mistral-common
原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/yun295814.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重