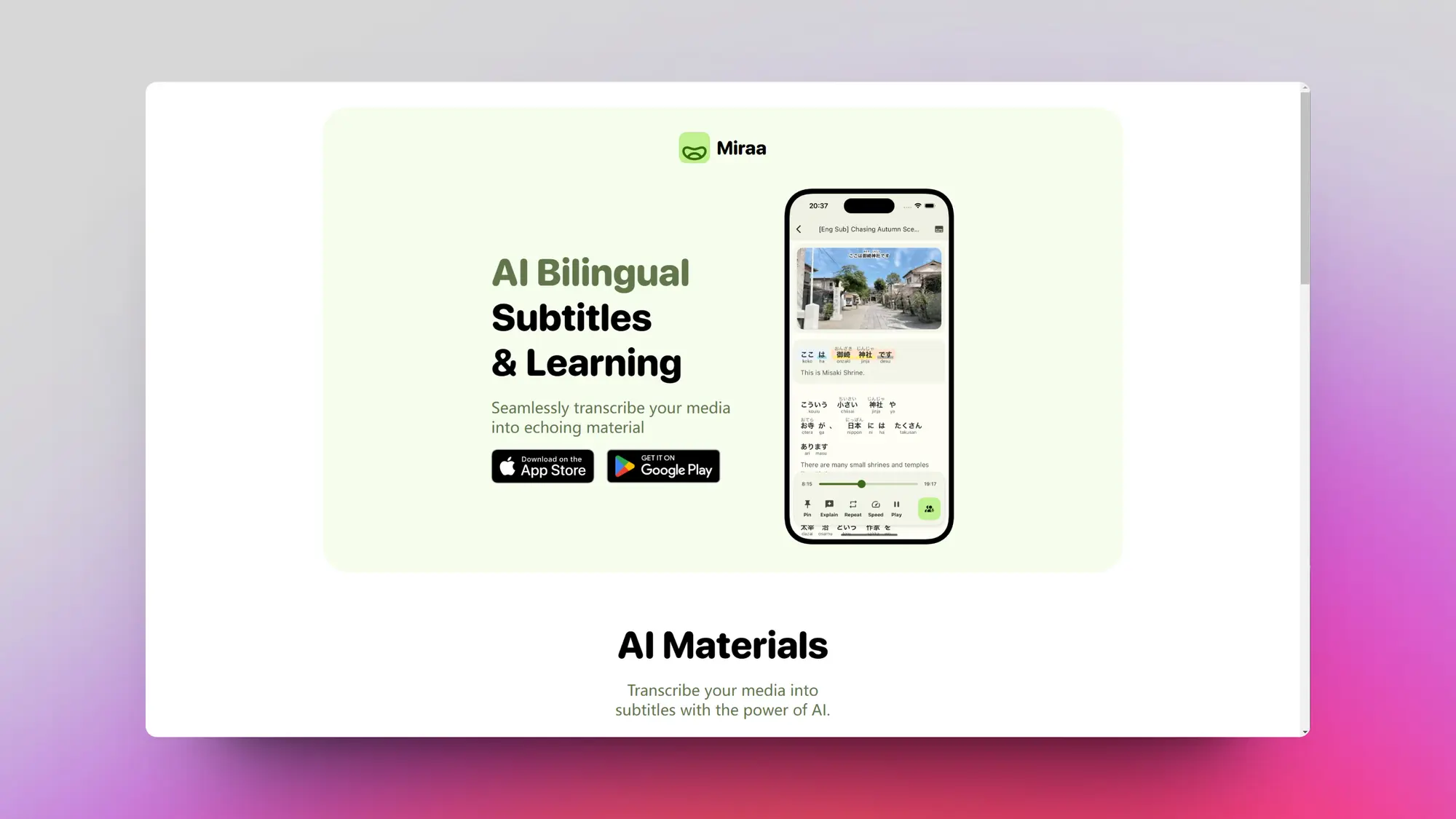
stability ai 其最新的stable video diffustion 视频开源模型!支持:
– 文本到视频
– 图像到视频
– 14 或 25 帧,576 x 1024分辨率
– 多视图生成
– 帧插值
– 支持3d 场景
– 通过 lora 控制摄像机
stability ai称正在开发一个新的网络平台,包括一个文本到视频的界面。这个工具将展示stable video diffusion在广告、教育、娱乐等多个领域的实际应用。
附原文
今天,我们发布了,这是我们第一个基于图像模型稳定扩散的生成视频基础模型。
这种最先进的生成式 ai 视频模型现已提供研究预览版,它代表了我们为各种类型的每个人创建模型的旅程中迈出的重要一步。
通过此研究版本,我们在 github 存储库上提供了稳定视频扩散的代码,并且可以在我们的 hugging face 页面上找到本地运行模型所需的权重。有关该模型技术能力的更多详细信息可以在我们的研究论文中找到。
适用于多种视频应用
我们的视频模型可以轻松适应各种下游任务,包括通过对多视图数据集进行微调从单个图像进行多视图合成。我们正在计划建立和扩展这个基础的各种模型,类似于围绕稳定扩散建立的生态系统。
从我们的微调视频模型中获取多视图生成示例
此外,今天,您可以在此处注册我们的候补名单,以访问即将推出的具有文本转视频界面的新网络体验。该工具展示了稳定视频扩散在广告、教育、娱乐等众多领域的实际应用。
具有竞争力的性能
稳定视频扩散以两种图像到视频模型的形式发布,能够以每秒 3 到 30 帧之间的可定制帧速率生成 14 和 25 帧。在以基础形式发布时,通过外部评估,我们发现这些模型超越了用户偏好研究中领先的封闭模型。

专供研究
虽然我们热切地用最新的进步来更新我们的模型,并努力吸收您的反馈,但我们强调,该模型现阶段不适用于现实世界或商业应用。您对安全和质量的见解和反馈对于完善此模型以使其最终发布非常重要。
这与我们之前以新方式发布的版本一致,我们期待与大家分享完整的版本。
项目链接
github:https://github.com/stability-ai/generative-models
论文:https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
huggingface:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/yun267355.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重