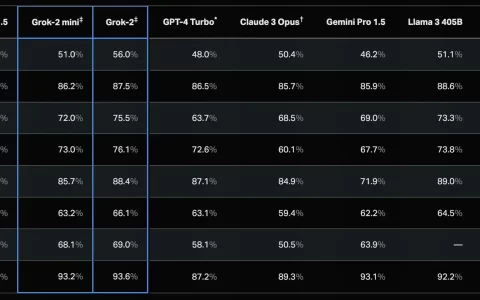
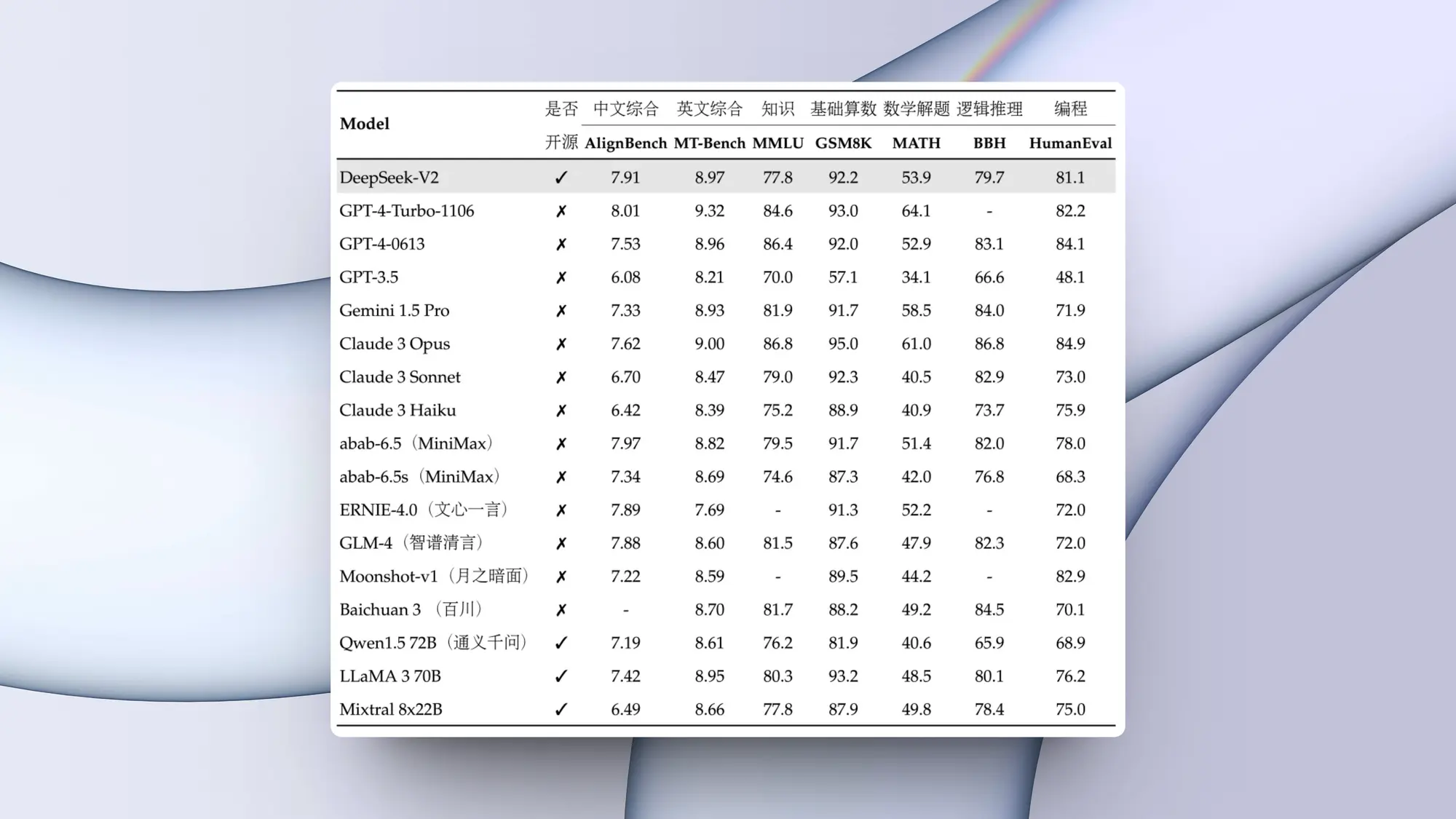
- voicecraft模型介绍:
voicecraft是一个先进的神经编解码语言模型,专门用于语音编辑和零样本文本到语音(tts)任务。该模型采用了transformer解码器架构,并引入了一个独特的令牌重排程序,该程序结合了因果掩蔽和延迟堆叠技术,使得模型能够在现有序列内生成内容。这种设计使得voicecraft在自然度方面与未编辑的录音几乎无法区分,并且在零样本tts任务上超越了以往的模型。 - 语音编辑任务:
语音编辑是voicecraft的核心功能之一,它允许用户修改语音记录中的特定部分,以匹配目标转录文本。这包括插入新词汇、删除不需要的部分或替换错误的词汇。通过这种方式,voicecraft能够生成与原始录音在自然度上几乎无法区分的编辑后语音,这对于内容创作者和教育工作者等用户来说非常有价值。 - 零样本文本到语音(tts)任务:
零样本tts是voicecraft的另一个重要功能,它允许模型在没有听过目标声音的情况下,仅根据目标转录和一小段参考录音来合成语音。这对于创建多样化的声音内容非常有用,尤其是在需要快速生成大量不同声音的情况下。 - 模型架构和训练方法:
voicecraft的架构基于编解码器,它首先将语音波形量化为一系列可学习的离散单元,然后使用transformer解码器来预测这些单元。通过因果掩蔽和延迟堆叠技术,模型能够在自回归序列预测中有效地利用双向上下文信息。这种训练方法使得模型在处理长序列时表现出色,并且能够生成高质量的语音输出。
项目地址:https://github.com/jasonppy/voicecraft?tab=readme-ov-file
原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/yun291862.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重